サービス概略
chatGPTのchatbotツールの開発が多く行われています。
回答の品質チェックはどのように行っていますか。
手作業で質問回答を行い、その回答を担当者が評価する方法が一般的かもしれません。
chatGPTの回答は毎回異なりますから、同じ質問をしても回答が毎回異なります。
そのため、テスト段階で大量の回答をチェックしなければなりません。
そう考える手作業での回答チェックでは必要な試行回数を行うことは困難だと思われます。

そもそもchatGPTを基盤としたchatbotの一番の課題はハルシネーション問題(AIが誤った回答をしてしまうこと)と呼ばれる「明らかに誤っている回答をしてしまう」ことです。
無作為抽出的な回答チェックではこの誤った回答の出現を阻止するためのプロンプトの改善は困難です。
なぜならこの誤った回答の出現は1%~10%程度と言われているため、同一質問に対しての複数回程度のチェックでは「誤った回答が出現」することがないことも多いからです。
GPT・BOTチェッカーはchatGPTによるテストによる大量の質問・回答の試行を行い、「誤った回答の出現」をさせます。
そのことにより、プロンプトの改善が可能になります。
このようにchatGPTをベースとするchatbotには「回答のチェック(分析)~プロンプト改善」の特別な方法が必用なのですが、これまではその明確な解決策がありませんでした。
GPT・BOTチェッカーはこの問題を解決するために、新しく「回答のチェック(分析)~プロンプト改善」のプロセスを開発しました。
<chatGPTの回答を分析するプロセス>
1-大量の回答チェックをchatGPTが行い集計を行う。
2-回答の品質を数値化
3-統計的に処理
以下に内容を説明します。
これにより皆さんのchatbot開発が工数削減でき、よりよい品質のchatbotづくりに貢献できればと思います。
サービス詳細
GPT・BOTチェッカーとは
ChatGPTベースのchatbotの品質を解析する新しいチェックツールです。 多くの回答テストを試行し、回答を分析し、統計的な考え方から不良回答を無くします。
大量の回答チェックをchatGPTが実施 !
ChatGPTを基盤としたchatbotの特性として、「揺らぎ」と呼ばれる同じ質問でも回答を毎回変えるという特性があります。つまり、質問・回答のチェックの試行回数をかなりのボリュームで行う必用があります。
そうすることで一定確率で発生する可能性のある品質の低い回答を発見することを試みます。
GPT・BOTチェッカーでは最低でも一つの質問に対し20回の試行回数が必用と考えます。
また、質問の種類も50種程度は必用だと考えています。
<推奨する最低試行回数> 50種×20回=1000回
大量の試行回数を処理するためにもchatGPTによる質問・回答テストを行います。
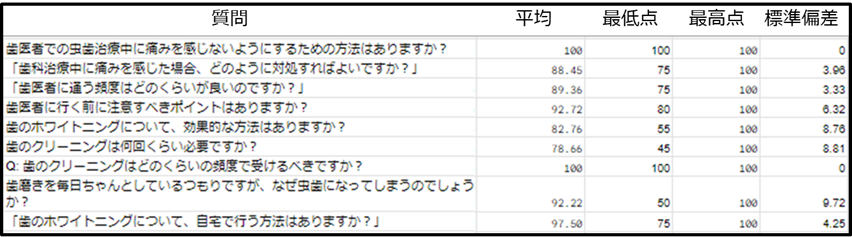
■GPT・BOTチェッカーの質問回答の集計表のサンプル

回答の品質(正答度合い)を数値化 !
回答の内容を検証するのに「担当者の主観」をたよりに無作為抽出的に質問・回答の内容をチェックすることが多くないでしょうか。
これでは、大量の質問・回答の品質をチェックするのに時間がかかります。
そこで、GPT・BOTチェッカーでは回答の正答度合いを数値化し、ガイドラインを設定しています。
GPT・BOTチェッカーでは70点以上を合格と考え、このガイドラインをchatGPTに学習させ採点に使用しています。
目標数値=スコア70以下の回答ゼロ(=確率的に無視できる状態)
■回答品質(正答度合い)の数値化のガイドライン

統計的に処理
工業生産品の不良品の発生率は統計的に考えて処理しています。
「ChatGPTを基盤としたchatbot」の回答も同じように不良回答の発生率を統計的に考えることができます。
標準偏差は下記の図にように分布します。
■標準偏差のバラツキ分布の図
※σ(シグマ)は標準偏差を表します。
標準偏差は試行結果の得点のバラツキを表し、正規分布に準じるものはこのバラツキに収まります。
平均から標準偏差の上下1倍のスコアの中に全体の68%が収まる。
平均から標準偏差の上下2倍のスコアの中に全体の95%が収まる。
平均から標準偏差の上下3倍のスコアの中に全体の99.7%が収まる。

結論として、上記の表の「正答度合いの数値化のガイドライン」において、下記を目指すことで、確率的にほぼ起こりえないとみなせる品質を達成することができます。
目標とする回答性能 平均90・標準偏差4.0
そうすることで、すべての回答の99.7%が78点、95%が82点以上の回答品質になります。
■平均点・標準偏差などの表サンプル
※参考 米国の医療機関でのchatbotの品質評価(google)の記事から
GoogleのAI部門であるDeepMindの論文が、極めて権威のある学術誌であるNatureに掲載された。
その内容によると
人間の臨床医の質問・回答に対する平均スコアである92.9%。
グーグルの開発したAIのMed-PaLMは92.6%スコア。
GoogleのLLM「PaLM」の派生モデルが上げた61.9%スコア
だったとのこと。
このことから、正答度合いが93%程度のスコアがあれば充分役に立つということではないでしょうか。
 まとめ
まとめ
上記のプロセスを通じ、テストの煩雑さを解決します。
式場の個別情報も提供可能(オプション)
■初回テスト料金
50質問の生成×20回の質問試行=1000回試行テスト=60,000円(税別)
■追加テスト料金
1問×20回の質問試行=20回試行テスト=2,000円(税別)
■最終テスト料金
50質問の生成×20回の質問試行=1000回試行テスト=30,000円(税別)
※価格設定はトライアル期間時のもので、予告なく変更する場合があります。 ※OPENAIのトークン料金がかかる場合があります。